- May 23, 2022
- Yanick Zeder
The problem of diversity
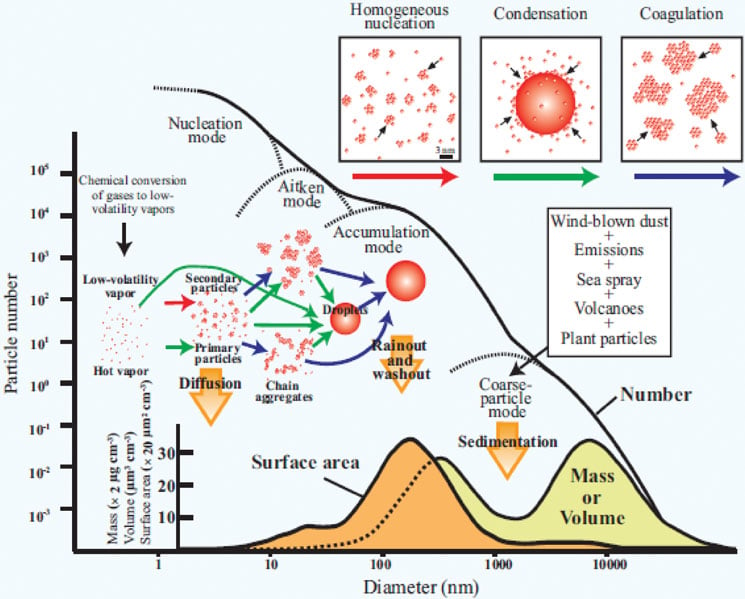
First, let’s start with a little background knowledge. When measuring aerosol particles, we realise pretty quickly how much material in the air is flying around. As shown in figure 1 There are all kinds of dust, combustion residues, pollen, spores, bacteria and much more. This mixture of aerosol particles is highly dependent on environmental conditions and can depend on the region, the time of day and the weather of the season among other things. In most cases, pollen makes up only a very small proportion of the total mixture.
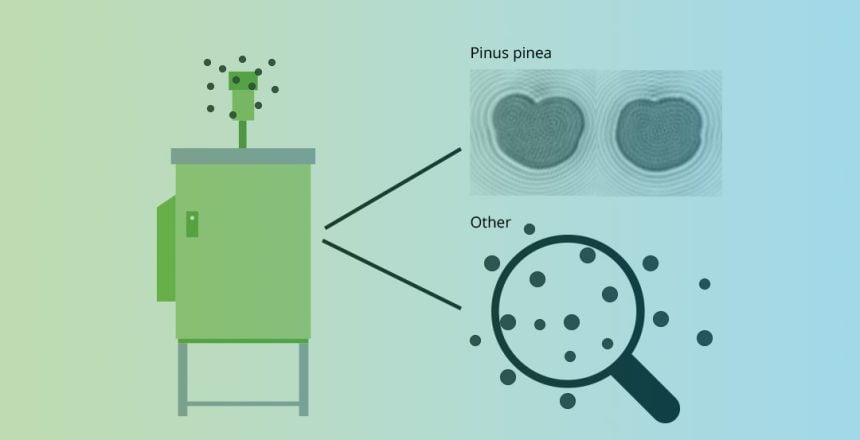
A real-time aerosol measurement system like SwisensPoleno now has the challenging task of processing the data from a diverse and very heterogeneous mixture in a meaningful way and recognising individual particle classes. For example, for automatic pollen identification in real time. It is precisely for such an application that classification algorithms come into play. We explain how such a classification algorithm works in the next section.
What does a classification algorithm do?
Now that we have established the prerequisites, we need to build up a basic understanding of a classification algorithm. Since we can fill whole books with this topic, we will try to give a rough overview here.
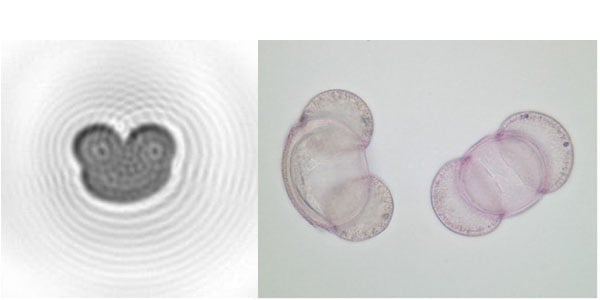
The SwisensPoleno algorithm takes the measurement data, looks at it and then explains to which class the measured aerosol particles belong. A class can correspond to a specific pollen type (e.g. Pinus). To accomplish this, it was presented with several thousand training data for the class “Pinus”. Essentially, the algorithm searches for features that characterise the data of this class. Given a sufficient amount of training data, the algorithm recognises that Pinus pollen has a heart-shaped form with a certain size and orientation as shown in figure 2. After this training process, we can give the algorithm new data to classify on its own. By matching the features found in the training with the new data, the algorithm determines a probability. This probability tells to what extent the new data belongs to the trained example class. In the example shown in figure 2 (reconstructed holographic image of Pinus, left), the identification algorithm would perhaps output Pinus with 98%, Fagus with 2% certainty and zero for the remaining classes.
What happens if we show the algorithm data from an aerosol particle for which it has never seen examples? The algorithm uses the same procedure as for any other particle before. It compares the features it found with the new data. Maybe a class has some similarities, and the algorithm assigns it to that class. This can lead to a wrong classification. It has detected a class of particles that was not present in the air. In statistics, this is called a “false positive”.
The advantages & disadvantages of machine learning
A great strength of machine learning is also a great weakness. What is meant is the autonomous recognition of relevant features from a set of data. Since a model is essentially a black box (see figure 3 below), we cannot determine exactly which features it has learned to distinguish classes. Therefore, it is almost impossible to check whether a classification is useful or not.

We have essentially two main options to combat that issue.
- We can add training examples of all possible classes that can occur in the air.
- We make sure that we only show the algorithm data that it has been trained to recognise.
In most cases, it is not possible to have a complete set of training examples ready for all particle types. We therefore need to limit the particles we show the algorithm and ensure that we only show it data from particles it has been trained to recognise. For the case of automatic pollen identification, we need to distinguish the total number of pollen from other aerosol particles on the one hand, and the individual pollen types on the other. This is where the pre-filter comes in, which helps us to separate pollen from other aerosol particles.
The Pollen Pre-Filter
The approach to pre-filtration of pollen and other aerosol particles is quite simple. Pollen usually has a compact, spherical shape, which is in great contrast to other aerosol particles. With this property alone, 98 % of the other aerosol particles can already be sorted out. However, there are exceptions that we have come across over the years. For example, desert dust grains can also look very spherical. Water droplets in fog also tend to be perfectly round. For such cases, we create datasets with these particle types and train the algorithm together with the pollen classes. For example, each of our pollen models currently in use is trained to distinguish water droplets.
To determine the roundness or compactness of a particle, we use the so-called “solidity measure” as explained in figure 4.
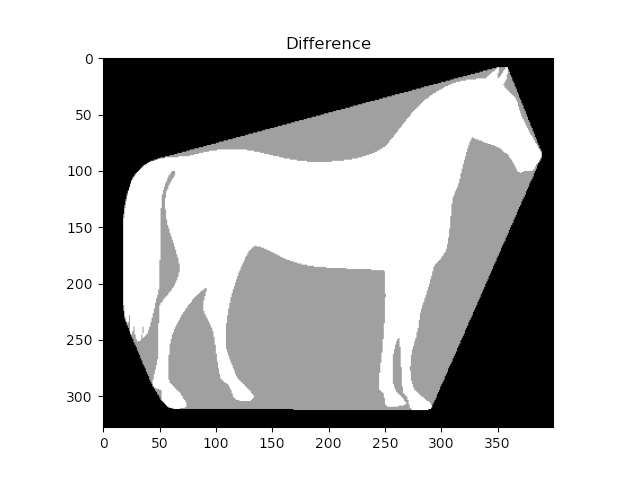
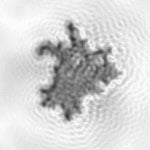
In the case of pollen identification, the solidity measure compares the area of the particles with its convex hull. A perfect sphere has a value of one. In the case of pollen, we have found that the solidity is usually well above 0.9, which is currently the standard value for the pre-filter. Dust grains, on the other hand, have significantly lower values. The particle in figure 5, for example, has a “solidity” of 0.6.
You can read more about the morphological particle properties of SwisensPoleno here.
In addition to this compactness filter, we have other characteristic values which can be assigned to a pollen grain. We know that pollen lies within a certain size range. This is either determined by an expert or we check the training data and look for the minimum size. These two simple conditions (compactness & size) are amazingly effective and easy to implement. To give a current example, exactly these filters are used for the automatic pollen monitoring network of MeteoSwiss, among others.
For other countries and regions, these values may need to be adjusted. At the same time, we recommend including fresh training data for the relevant pollen in this region.
We hope you now have a better understanding of how and why we use a pre-filter for the automatic identification of aerosol particles and pollen. Let us know if you would like more insight into any aspect of this topic. We will be happy to provide you with further information.